The aggregation of data by EDI are based on their similarities (the nonparametric approach used hasn’t
been found in the scientific literature and in all the algorithms studied) makes it possible to identify a
group of ‘very different transactions’, which must be examined to see if a new system and approach to
money laundering has been created. When historical pre-classified records on fraudulent transactions is
available, the technology determines which transaction segments are closest to the ones previously
identified and allows data operators to focus on these.
The possibility of processing large arrays of data allows you to perform a test within a few hours, thereby
eliminating the possibility that financial or credit institutions are used for money laundering.
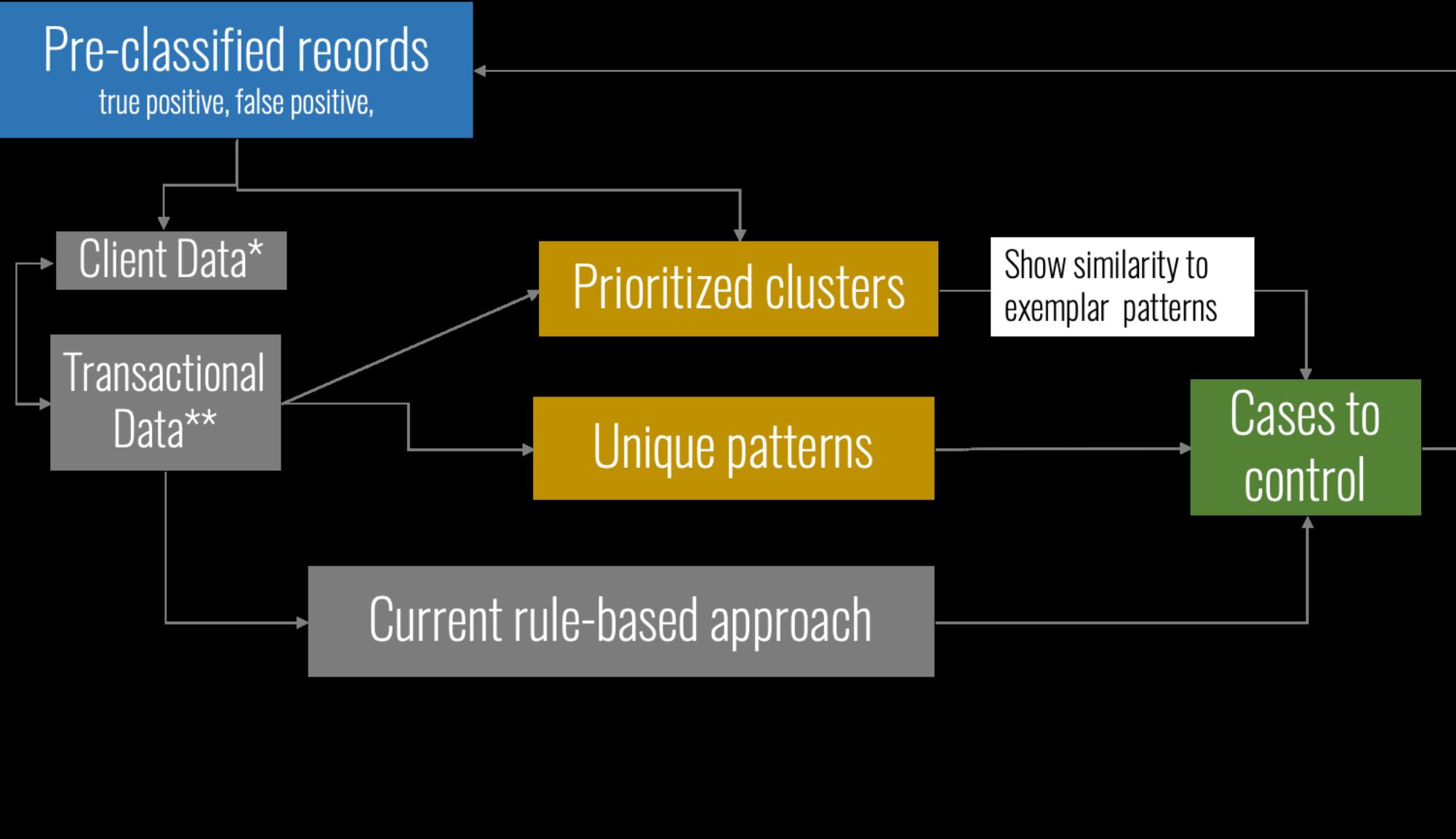
The EDI data processing and analysis technology consists of three components, some of which have been
completed and the others are marked on synthetic data.
