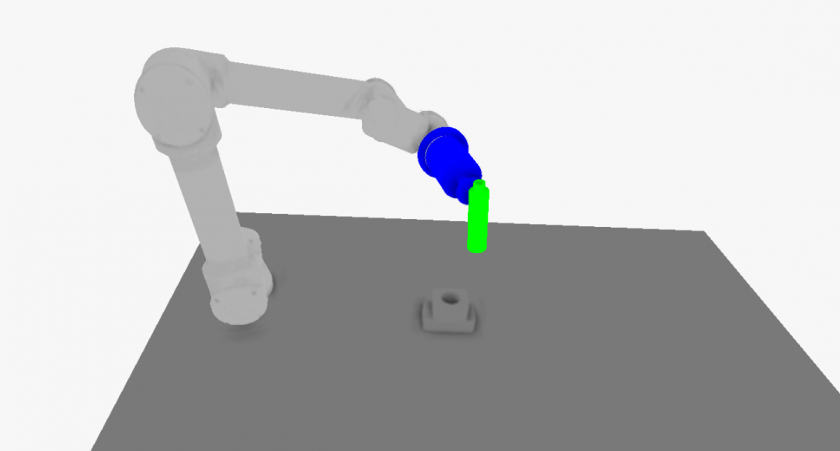
Simulated UR5 robotic arm inserting a bottle into a socket. The motion trajectory was learned end-to-end through gradient-based optimisation in a differentiable physics simulator.
Robotic arm performing a bottle-into-socket insertion in simulation. The control policy is trained inside a differentiable physics simulator and produces smooth, sub-millimetre-accurate trajectories that adapt in real time to moving targets – for example, bottles arriving on a conveyor.
Value Proposition
Differentiable-Physics Training for Precision Robot Motion Planning is an EDI-developed AI training method for industrial robotic arms that learns smooth, sub-millimetre-accurate motion trajectories directly from a physics simulator with full gradient backpropagation. Unlike trial-and-error reinforcement learning, the system exploits gradient information from the simulator itself, yielding stable, high-speed training (roughly one to two orders of magnitude fewer training steps than RL) and motion controllers that compute the next action in 0.3 ms – fast enough to handle moving targets such as bottles arriving on a conveyor belt without manual feeding.
Business and Innovation Perspective
Challenge
Many high-volume industrial production lines – cosmetics filling, beverage bottling, pharmaceutical packaging, food-grade containers – still rely on manual feeding of objects onto conveyors and into fixtures, because conventional automation is too rigid to handle the variability in object pose, conveyor speed and target geometry. Manual feeding introduces variability, limits throughput, drives up operational cost, and exposes workers to repetitive strain. Automating it requires a robotic system that combines real-time target tracking with sub-millimetre placement accuracy and smooth, high-speed trajectories – and that can be re-trained quickly when products change.
Existing Alternatives
Current industry approaches each have substantial drawbacks. Heuristic and sampling-based motion planners (RRT, PRM, optimisation over splines) generate trajectories analytically, but they require careful task-specific tuning, struggle with dynamic targets and produce jerky trajectories that have to be smoothed in post-processing. Reinforcement learning (RL) can in principle handle dynamic targets, but is sample-inefficient, slow to converge (millions of trial-and-error steps), and the resulting policies are hard to verify for industrial safety standards. Imitation learning from human demonstration captures dexterity but plateaus at the demonstrator’s accuracy and offers no formal guarantee of constraint satisfaction. Open-loop pre-recorded trajectories are precise on a fixed scene but break the moment the target starts moving.
EDI Solution and Unique Value
The EDI training method uses a differentiable physics simulator in which every step of the simulation – kinematics, dynamics, contact and joint limits – is differentiable with respect to the neural-network controller’s parameters. Trajectories, smoothness penalties, start- and goal-state constraints and non-penetration constraints are all expressed in a single differentiable loss function, and gradient backpropagation runs through the entire unrolled simulation. The controller itself is a small neural network that takes the current robot state, the target position and velocity, and a normalised time index, and produces a joint-action command in 0.3 ms per call. Time-to-completion is minimised by iteratively shrinking the trajectory length until the constraints can no longer be satisfied – yielding the shortest feasible motion. Random state noise is injected during training to improve robustness and prepare for sim-to-real transfer.
The unique combination of (a) full gradient backpropagation through the physics simulator, (b) constraints (non-penetration, start/goal pose, smoothness) expressed in a differentiable way, and (c) a compact neural controller, delivers simultaneously fast training, smooth high-speed trajectories, sub-millimetre placement accuracy and real-time inference – properties that none of the existing alternatives provides together.
Quantitative comparison on the bottle-into-socket insertion task (UR5, Nimble Physics, average of 100 runs):

Technology Readiness Level (TRL)
TRL 3–4 – Method implemented and validated in simulation on the bottle-into-socket insertion task in two scenarios (static and moving target) using the Nimble Physics differentiable simulator and a simulated UR5 industrial robot arm. Outperforms a reinforcement-learning baseline in both convergence speed and trajectory smoothness. Integration with a 6-DOF pose-estimation pipeline, a program-synthesis layer for skill composition, and real-robot deployment (sim-to-real with domain randomisation) is the next step.
Developed within AIMS5.0 – Advancing Integrated Manufacturing Systems (Industry 5.0), supported by the Chips Joint Undertaking and its members, with top-up funding from National Funding Authorities of participating countries. Grant agreement No. 101112089.
Technical Specification
Operating Principle
Training-loss curves for the static-socket and moving-socket scenarios. Loss drops from ~0.15 to under 0.02 within roughly 100,000 training steps and remains stable thereafter – orders of magnitude faster than reinforcement learning, which typically needs millions of steps to reach the same performance.
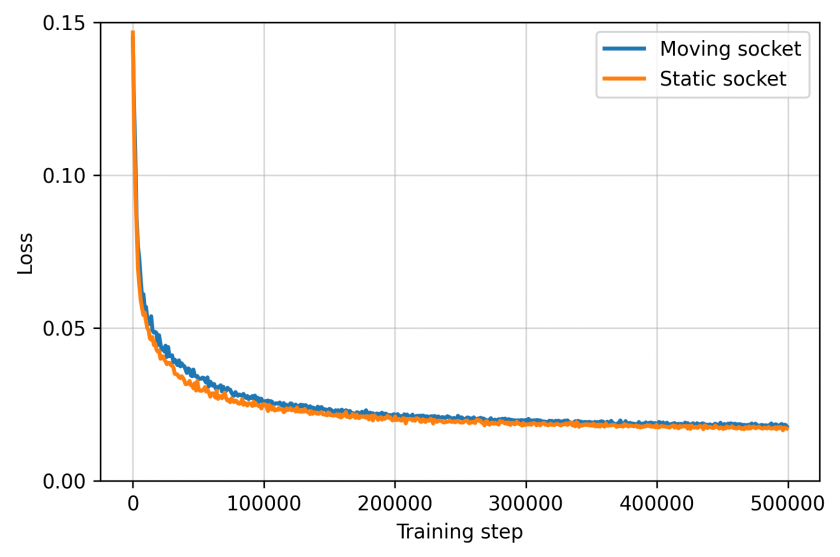
Training dynamics in both scenarios – loss falls quickly and stays stable.
The system is trained inside a fully differentiable rigid-body simulator. At each timestep, the neural controller observes the robot’s joint state, the target position, the target velocity and a normalised time index, and outputs joint forces. The simulator unrolls the resulting trajectory for typically 30 timesteps at 10 ms per step. A composite loss is computed from this trajectory: a smoothness term (sum of squared joint velocities), start- and goal-state errors (squared Cartesian distance + orientation alignment around the vertical axis), and differentiable non-penetration constraints. Gradients are backpropagated through the entire unrolled simulation to update the controller’s weights using the Adam optimiser. To find the fastest feasible motion, the trajectory length is iteratively reduced until the constraints can no longer be satisfied. State noise injected during training improves robustness and the eventual sim-to-real transfer.
Empirical validation on the bottle-into-socket insertion task (100 runs per condition) gives a final-point placement error of 1.42 ± 0.77 mm with a 0.21° orientation error for the static-target scenario, and 1.55 ± 0.91 mm / 0.23° for the moving-target scenario, with the trained policy producing each action in 0.3 ms.
Parameters

Cooperation Modes
We see three transfer paths for partners interested in the technology:
1. Licensing – a non-exclusive or exclusive licence to use the EDI training pipeline, loss formulations and controller architecture, including the right to extend and customise them for the partner’s robot platform and task family.
2. Contract research / joint development – adaptation of the method to the partner’s specific robot model, end-effector, sensor stack, asset library and production environment; sim-to-real engineering with domain randomisation; integration with existing motion-control, vision and MES/ERP layers; extension to additional skill primitives (kitting, assembly, machine tending).
3. Assignment – outright transfer of the underlying intellectual property (know-how) to a strategic partner under a negotiated agreement.
EDI welcomes early conversations with system integrators, robot OEMs, and end-users in bottling, packaging, cosmetics, pharmaceutical and other industries where the manual feeding of moving products is currently the throughput bottleneck.
Funded within the AIMS5.0 project (Chips JU, grant agreement No. 101112089).