Simulēts UR5 robotmanipulators ievieto pudeli ligzdā. Kustību trajektorija tiek apgūta no gala līdz galam ar gradientu balstītu optimizāciju diferencējamā fizikas simulatorā.
Robotmanipulators simulācijā ievieto pudeli ligzdā. Vadības neironu tīkls tiek apmācīts diferencējamā fizikas simulatorā un rada gludas, līdz milimetra desmitdaļai precīzas trajektorijas, kas reāllaikā pielāgojas kustīgiem mērķiem, piemēram, pudelēm, kas pienāk pa konveijera lenti.
Vērtības piedāvājums
Apmācība ar diferencējamu fiziku precīzai robota kustību plānošanai ir EDI izstrādāta MI apmācības metode industriālajiem robotmanipulatoriem. Tā iegūst gludas, līdz milimetra desmitdaļai precīzas kustību trajektorijas tieši no fizikas simulatora, izmantojot pilnīgu gradientu atpakaļizplatīšanu. Atšķirībā no uz mēģinājumiem un kļūdām balstītas pastiprināšanas mācīšanās sistēma izmanto paša simulatora gradientu informāciju, nodrošinot stabilu un ātru apmācību – aptuveni par vienu līdz divām lieluma kārtām mazāk apmācības soļu nekā pastiprināšanas mācīšanās gadījumā. Vadības tīkls aprēķina nākamo darbību 0,3 ms laikā, kas ir pietiekami ātri, lai sistēma spētu strādāt ar kustīgiem mērķiem, piemēram, pudelēm, kas pienāk pa konveijera lenti, bez manuālas padeves.
Biznesa un inovācijas perspektīva
Izaicinājums
Daudzas liela apjoma rūpnieciskās ražošanas līnijas – kosmētikas produktu pildīšana, dzērienu pildīšana pudelēs, farmaceitisko produktu iepakošana un pārtikas konteineru apstrāde – joprojām paļaujas uz manuālu objektu padevi konveijeriem un fiksatoriem, jo tradicionālā automatizācija ir pārāk neelastīga, lai tiktu galā ar mainīgu objektu pozu, konveijera ātrumu un mērķa ģeometriju. Manuālā padeve rada svārstības, ierobežo caurlaidspēju, palielina ekspluatācijas izmaksas un pakļauj darbiniekus atkārtotai fiziskai slodzei. Lai šo procesu automatizētu, ir nepieciešama robotu sistēma, kas apvieno mērķa izsekošanu reāllaikā, novietošanas precizitāti līdz milimetra desmitdaļai un gludas, ātras trajektorijas, kā arī ir ātri pārapmācāma, mainoties produktiem.
Esošās alternatīvas
Pašreizējām nozares pieejām ir būtiski trūkumi. Heiristiskie un izlasē balstītie kustību plānotāji ģenerē trajektorijas analītiski, taču prasa rūpīgu, konkrētam uzdevumam pielāgotu regulēšanu, nespēj efektīvi strādāt ar kustīgiem mērķiem un rada nevienmērīgas trajektorijas, kas pēc tam ir jāizlīdzina. Pastiprināšanas mācīšanās (RL) principā var tikt galā ar kustīgiem mērķiem, taču tā ir neefektīva paraugu izmantošanas ziņā – nepieciešami miljoniem mēģinājumu un kļūdu soļu –, lēni konverģē, un iegūtās vadības politikas ir grūti sertificēt atbilstoši rūpniecības drošības standartiem. Imitatīvā mācīšanās no cilvēka demonstrācijām ļauj pārņemt veiklas kustības, taču nesniedz precīzāku rezultātu par pašu demonstrētāju un nepiedāvā formālas garantijas par ierobežojumu ievērošanu. Iepriekš ierakstītas atvērtās cilpas trajektorijas ir precīzas fiksētā vidē, taču pārstāj darboties, tiklīdz mērķis sāk kustēties.
EDI risinājums un unikālā vērtība
EDI apmācības metode izmanto **diferencējamu fizikas simulatoru**, kurā katrs simulācijas solis — kinemātika, dinamika, kontakts un locītavu ierobežojumi — ir diferencējams attiecībā pret neironu tīkla vadības parametriem. Trajektorijas, gluduma soda funkcijas, sākuma un mērķa stāvokļa ierobežojumi, kā arī savstarpējas iespiešanās nepieļaušanas ierobežojumi tiek izteikti vienā diferencējamā zudumu funkcijā. Gradientu atpakaļizplatīšana notiek caur visu izvērsto simulāciju. Vadības lēmumus īsteno neliels neironu tīkls, kas saņem pašreizējo robota stāvokli, mērķa pozīciju un ātrumu, kā arī normalizētu laika indeksu, un **0,3 ms** laikā izvada locītavu vadības komandu. Izpildes laiks tiek minimizēts, iteratīvi saīsinot trajektorijas garumu, līdz ierobežojumus vairs nav iespējams izpildīt. Tādējādi tiek iegūta īsākā iespējamā kustība. Apmācības laikā stāvokļa datiem tiek pievienots nejaušs troksnis, lai uzlabotu robustumu un sagatavotos pārejai no simulācijas uz reālu robotu.
Unikālā kombinācija, kas ietver (a) pilnīgu gradientu atpakaļizplatīšanu caur fizikas simulatoru, (b) diferencējamā veidā izteiktus ierobežojumus — savstarpējas iespiešanās nepieļaušanu, sākuma un mērķa pozu, kā arī gludumu — un (c) kompaktu neironu tīkla vadības politiku, vienlaikus nodrošina **ātru apmācību**, **gludas ātrgaitas trajektorijas**, **novietošanas precizitāti līdz milimetra desmitdaļai** un **reāllaika inferenci**. Šādu īpašību kopumu nesniedz neviena no esošajām alternatīvām.
Kvantitatīvs salīdzinājums pudeles ievietošanas ligzdā uzdevumā (UR5, Nimble Physics, vidējās vērtības 100 izpildījumos):
| Parametrs | RL atskaites punkts / heiristiskais plānotājs | EDI diferencējamās fizikas metode |
| Apmācības soļi līdz konverģencei (statisks mērķis) | ~2–4 M (RL, veiksmes līmenis nostabilizējas pie ≈ 95 %) | ~100 K (≈ 20× mazāk) |
| Apmācības soļi līdz konverģencei (kustīgs mērķis) | 8 M+ (RL, veiksmes līmenis nostabilizējas pie ≈ 90 %) | ~100 K – stabila, gluda konverģence |
| Galapunkta novietošanas kļūda (statiska ligzda) | RL / heiristiskie plānotāji: parasti vairāki | 1,42 ± 0,77 mm |
| Galapunkta novietošanas kļūda (kustīga ligzda) | RL / heiristiskie plānotāji: parasti vairāki mm | 1,55 ± 0,91 mm |
| Galapunkta orientācijas kļūda | Bieži netiek norādīta vai ir grādu mērogā | 0,21°–0,23° |
| Inferences laiks vienai darbībai | Mainīgs, milisekunžu mērogā | 0,3 ms |
| Trajektorijas gludums | RL: oscilējoša; heiristiskā metode: nevienmērīga | Gluda (locītavu ātrumu² zudums) |
| Ierobežojumu apstrāde | Mīksti ierobežojumi, kas apgūti ar atalgojumu | Diferencējami stingro ierobežojumu sodi |
| Pārapmācība jaunam uzdevuma variantam | No stundām līdz dienām | Minūtes (mazs tīkls, ātra konverģence) |
Tehnoloģijas gatavības līmenis (TRL)
TRL 3–4 – metode ir ieviesta un validēta simulācijā pudeles ievietošanas ligzdā uzdevumam divos scenārijos: ar statisku un kustīgu mērķi. Izmantots Nimble Physics diferencējamais simulators un simulēts UR5 industriālais robotmanipulators. Metode pārspēj pastiprināšanas mācīšanās atskaites punktu gan konverģences ātruma, gan trajektorijas gluduma ziņā. Nākamais solis ir integrācija ar 6 brīvības pakāpju pozas novērtēšanas plūsmu un programmu sintēzes slāni prasmju kompozīcijai, kā arī izvietošana uz reāla robota, nodrošinot pāreju no simulācijas uz realitāti ar domēna nejaušināšanu.
Izstrādāts projekta AIMS5.0 – Advancing Integrated Manufacturing Systems (Industry 5.0) ietvaros. Projektu atbalsta Chips Joint Undertaking un tā dalībnieki, kā arī iesaistīto valstu nacionālās finansēšanas iestādes. Granta līguma Nr. 101112089.
Tehniskā specifikācija
Darbības princips
Apmācības zudumu līknes statiskās ligzdas un kustīgās ligzdas scenārijiem. Zudums samazinās no ~0,15 līdz mazāk nekā 0,02 aptuveni 100 000 apmācības soļos un saglabājas stabils – par vairākām lieluma kārtām ātrāk nekā pastiprināšanas mācīšanās gadījumā, kur parasti vajadzīgi miljoniem soļu, lai sasniegtu tādu pašu rezultātu.
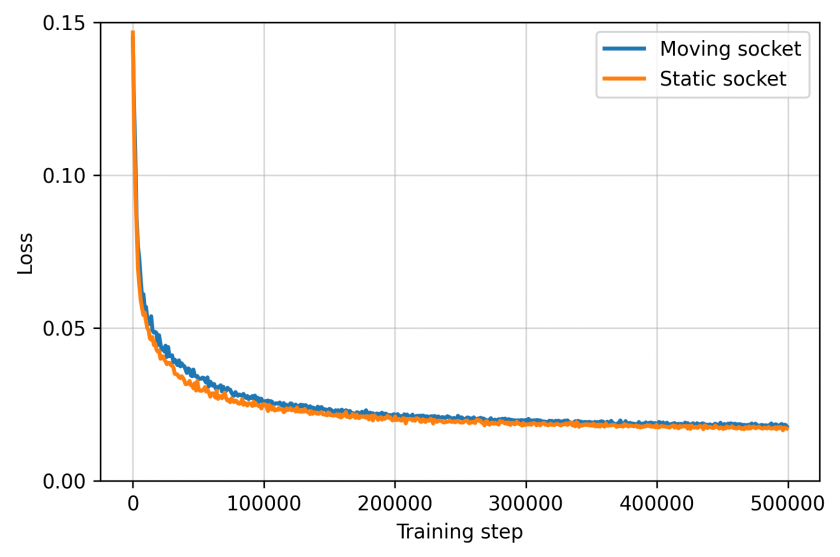
Apmācības dinamika abos scenārijos – zudums strauji samazinās un saglabājas stabils.
Sistēma tiek apmācīta pilnībā diferencējamā cieto ķermeņu simulatorā. Katrā laika solī neironu tīkla vadības politika novēro robota locītavu stāvokli, mērķa pozīciju, mērķa ātrumu un normalizētu laika indeksu un izvada locītavu spēkus. Simulators izvērš iegūto trajektoriju, parasti izmantojot 30 laika soļus pa 10 ms. No šīs trajektorijas tiek aprēķināta saliktā zudumu funkcija: gluduma loceklis (locītavu ātrumu kvadrātu summa), sākuma un mērķa stāvokļa kļūdas (Dekarta attāluma kvadrāts un orientācijas saskaņa ap vertikālo asi), kā arī diferencējami savstarpējas iespiešanās nepieļaušanas ierobežojumi. Gradienti tiek atpakaļizplatīti caur visu izvērsto simulāciju, lai atjauninātu vadības politikas svarus, izmantojot Adam optimizētāju. Lai atrastu ātrāko iespējamo kustību, trajektorijas garums tiek iteratīvi samazināts, līdz ierobežojumus vairs nav iespējams izpildīt. Apmācības laikā ievadītais stāvokļa troksnis uzlabo robustumu un atvieglo pāreju no simulācijas uz reālu robotu.
Empīriskajā validācijā pudeles ievietošanas ligzdā uzdevumā – 100 izpildījumi katram nosacījumam – statiskā mērķa scenārijā iegūta galapunkta novietošanas kļūda 1,42 ± 0,77 mm un orientācijas kļūda 0,21°, savukārt kustīgā mērķa scenārijā – attiecīgi 1,55 ± 0,91 mm un 0,23°. Apmācītā vadības politika katru darbību aprēķina 0,3 ms laikā.
Parametri
| Parametrs | Vērtība / apraksts |
| Validētā robota platforma | Universal Robots UR5 (6 brīvības pakāpju manipulators), simulēts |
| Simulācijas dzinējs | Nimble Physics – diferencējams cieto ķermeņu simulators |
| Laika diskretizācija | 10 ms vienam solim; tipiska trajektorija ≈ 30 soļi (0,3 s) |
| Vadības tīkla arhitektūra | Tiešās izplatīšanas tīkls ar 1 slēpto slāni un 256 neironiem; nelineāras aktivācijas |
| Vadības tīkla ievades | Locītavu stāvoklis, mērķa pozīcija, mērķa ātrums, normalizēts laika solis |
| Vadības tīkla izvade | Locītavu darbības (spēki / griezes momenti) |
| Optimizētājs | Adam, mācīšanās ātrums 1 × 10⁻³ |
| Apmācības soļi līdz konverģencei | ~100 000 (gan statiskā, gan kustīgā mērķa scenārijā) |
| Inferences laiks vienai darbībai | 0,3 ms |
| Validētie uzdevumi | Pudeles ievietošana ligzdā ar statisku mērķi un ar mērķi, kas kustas ar nemainīgu, robotam nezināmu ātrumu |
| Galapunkta novietošanas precizitāte (100 izpildījumi) | 1,42 ± 0,77 mm (statisks mērķis); 1,55 ± 0,91 mm (kustīgs mērķis) |
| Galapunkta orientācijas precizitāte (100 izpildījumi | 0,21° (statisks mērķis); 0,23° (kustīgs mērķis) |
| Operētājsistēma | Linux, x86-64 ar NVIDIA GPU |
Sadarbības veidi
Mēs redzam trīs tehnoloģijas pārneses ceļus partneriem:
- Licencēšana – neekskluzīva vai ekskluzīva licence EDI apmācības plūsmas, zudumu formulējumu un vadības tīkla arhitektūras izmantošanai, tostarp tiesības tos paplašināt un pielāgot partnera robota platformai un uzdevumu saimei.
- Līgumpētniecība / kopīga izstrāde – metodes pielāgošana partnera konkrētajam robota modelim, gala efektoram, sensoru kopumam, objektu bibliotēkai un ražošanas videi; pārejas no simulācijas uz realitāti inženierija ar domēna nejaušināšanu; integrācija ar esošajiem kustību vadības, redzes un MES/ERP slāņiem; paplašināšana ar papildu prasmju primitīviem, piemēram, komplektēšanu, montāžu un mašīnu apkalpošanu.
- Atsavināšana – pamatā esošā intelektuālā īpašuma jeb zinātības tieša pārdošana stratēģiskajam partnerim saskaņā ar atsevišķi noslēgtu līgumu.
EDI ir gatavs sākotnējām sarunām ar sistēmu integratoriem, robotu OEM ražotājiem un galalietotājiem pudeļu pildīšanas, iepakošanas, kosmētikas, farmaceitikas un citās nozarēs, kurās manuāla kustīgo produktu padeve patlaban ir apgrūtinoša.
Finansēts AIMS5.0 projekta ietvaros (Chips JU, granta līgums Nr. 101112089).