European Regional Development Fund Operational Programme “Growth and Employment”. 1.2.1. specific support goal “To increase Investments of Private Sector in R&D” ; measure 1.2.1.2. “Support for Improvement of Technology Transfer System” Project “Silicon IP Design House” No. KC-PI-2020/12. Agreement with Investment and Development Agency about participating in Technology Transfer measure No. KC-L-2017/14.
![]()
![]() Background
Background
In 1965, an American engineer and businessman Gordon Moore made a prediction in a magazine article “Cramming more components onto integrated circuits” that would influence the progress of IC (Integrated Circuit) development. At the time, he anticipated that the number of transistors “crammed” into an IC would double every year and projected that this rate would continue at least for the next decade. In 1975, he modified his claim, thus, postulating an empirical relationship that is now known as Moore’s Law – the transistor count in an IC doubles every two years. As the transistor count increased, the computer chip performance was predicted by Moore’s colleague David House to double every 18 months.
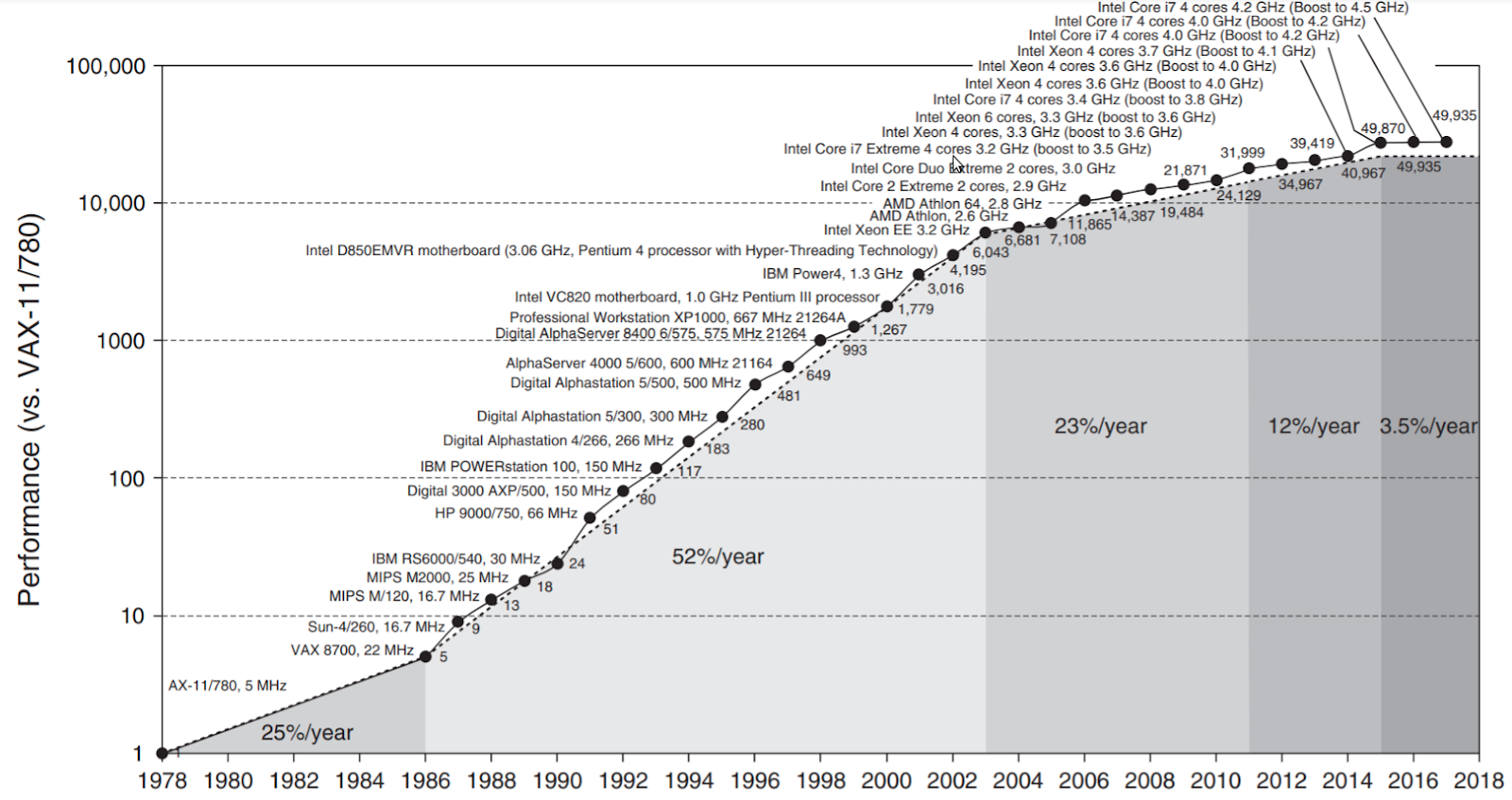 Processor performance growth evaluated using SPEC integer benchmarks
Processor performance growth evaluated using SPEC integer benchmarks
(the colored sections show the performance growth rates per year).
As the transistor density in an IC continues to lag behind what Moore’s Law anticipated with the continued processor yearly performance increase declining, we are entering what some call Post Moore’s Law Era.
Now a new question arises – what’s next for computing? While quantum computing is still on its way, the next step to increase computational performance is to develop domain-specific architectures or domain-specific accelerators. While ASICs (Application-Specific Integrated Circuit) are utilized to perform a single function and solve a specific problem, accelerators are tailored to accelerate certain parts of an application which can easily outperform general-purpose processors in that particular task.
Objective
SilHouse team aims to bring application-specific accelerator solutions to meet the current demand for high-performance, low latency and power-efficient computing while keeping the development time and costs to a minimum. The developed acceleration solutions consist of customized versions of our modular accelerator components, tailored to fit the specified requirements.
Technology
EDI has developed a great amount of IP cores for various computer vision and signal processing needs. Most notably – lens distortion correction, feature extraction and matching, perspective transformation, sparse optical flow and image fusion IP cores. All of our solutions have been developed to solve a specific problem, therefore, we need to make them commercially “interesting” by implementing additional features and configuration flexibility. The most notable of our image processing IP cores:
Image transformation (with digital zoom, rescaling, and windowing functions),
Hardware bicubic (high-quality) image interpolation (as a part of image transformation core, but can be separated),
Bayer camera sensor image debayering/demosaicing,
Dead pixel correction,
Histogram correction and linearization,
Image filtering (fully pipelined, low latency, image convolution with a kernel),
Fixed-pattern noise correction.
Commercialization
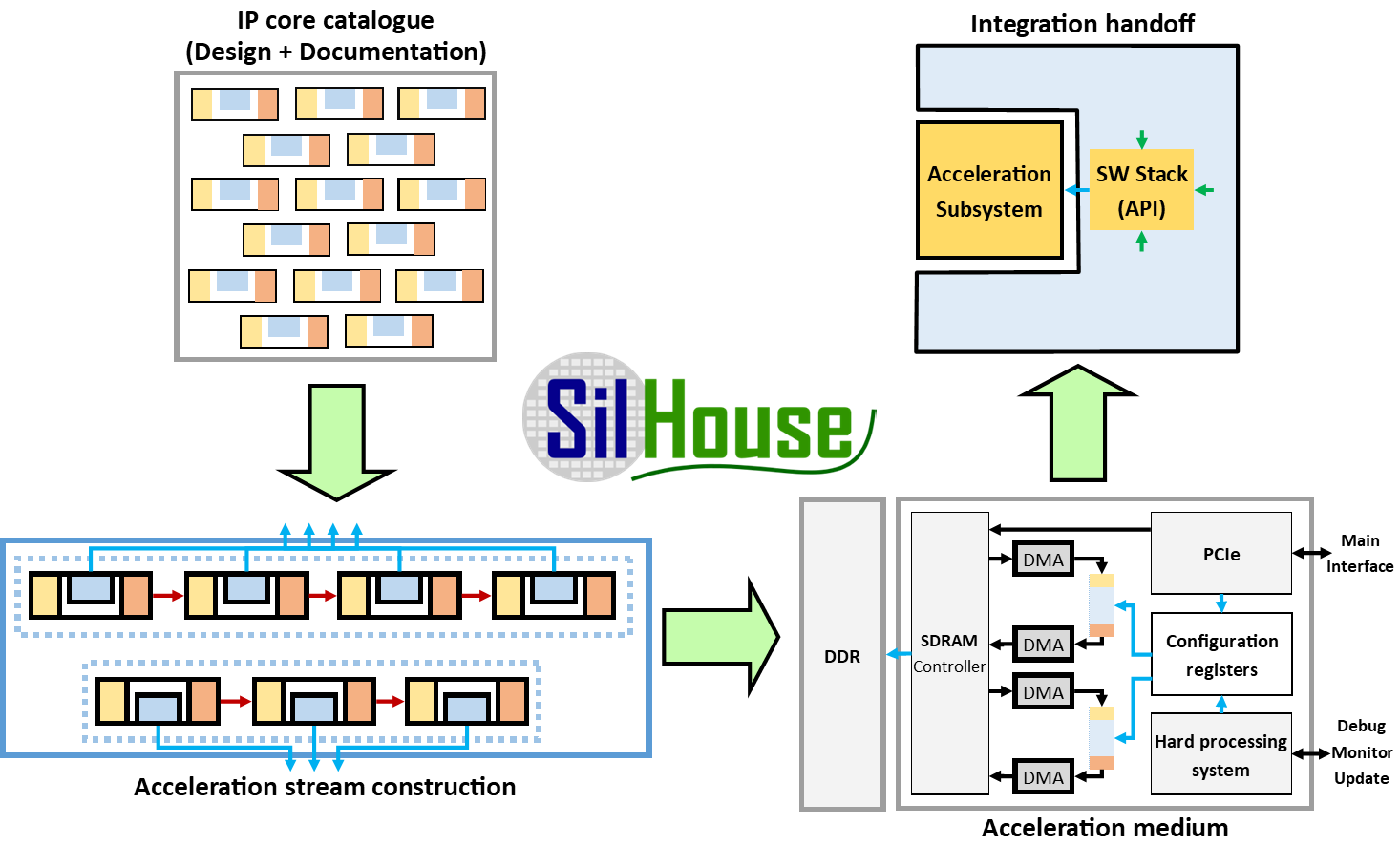 The concept of SilHouse Accelerator Toolbox for accelerator system design.
The concept of SilHouse Accelerator Toolbox for accelerator system design.
The accelerator design process of the proposed system is shown in Figure 1.2. We can divide the process into four steps:
1. IP core catalogue: During our research in computer vision and signal processing, EDI has developed a vast amount of specialized components or IP cores, most notably, lens distortion correction, image transformation, feature extraction. A more in-depth overview of the developed IP cores can be read in Section 1.3. The components are designed with modularity in mind, therefore they are designed with a common data exchange interface – AMBA AXI4-Stream [17]. This allows for easy interconnection between any of the components. Of course, the overall design process is not limited to the use of EDI IP cores and IP cores from other vendors can be utilized.
2. Acceleration stream construction: Following the defined requirements, we pick from our IP core catalogue the needed components and, if needed, design the missing ones to create a data processing pipeline for the defined task. By using the components from our IP core catalogue, we reduce the design time and cost it would take if we had to design it from ground-up.
3. Acceleration medium: With the data processing pipeline ready, we design or adapt already made accelerator platform for the integration in the relevant environment. The designed platform will either function as a standalone or as an addon device, in case we upgrade an existing system. In the latter case, the accelerator platform would have a suitable communication interface to exchange data between the accelerator and the system, such as PCIe, USB, Ethernet, etc.
4. Integration handoff: The platform with the designed accelerator and its accompanying software libraries is ready to be integrated into the system. The software libraries and the documentation ensures straightforward and simple integration in the existing system.
Main technical challenges of the project
– Development of a custom DMA engine,
– IP protection mechanism,
– Accelerator aggregation and design tools,
– Development of documentation,
– Linux-based driver and library design/development,
– Silicon-verification of the accelerator concept.
Participating scientists



